The HtmlAgilityPack (HAP) has been around for some time now, and is available via Nuget. You can install it using the command
install-package htmlagilitypack
HAP accepts HTML as a string, file, stream or TextReader object. The HTML is loaded into an HtmlDocument object using the Load method for streams, files and the TextReader option, and the LoadHtml method for loading HTML represented as a string. The two most commonly used methods are those that load a file or string:
var html = new HtmlDocument(); html.Load(@"C:\HtmlDocs\test.html"); // load a file html.LoadHtml(new WebClient().DownloadString("http://www.somedomain.com")); // load a string
Querying the DOM
Once you have loaded the HTML to be parsed, you can access it via the DocumentNode property of the HtmlDocument which returns the root element. From there, you can use LINQ (or XPath) to query the document, or more specifically, the collection of HtmlNode objects returned by the Descendants() method:
var html = new HtmlDocument(); html.LoadHtml(new WebClient().DownloadString("http://www.asp.net")); var root = html.DocumentNode; var nodes = root.Descendants(); var totalNodes = nodes.Count();
The code above returns the total number of HtmlNode objects (or HTML elements) found in the document. You can filter them in a number of ways. For example, you can pass a tag name to the Descendants method to filter by that tag. The following snippet queries the document for anchor tags and unordered lists:
var html = new HtmlDocument(); html.LoadHtml(new WebClient().DownloadString("http://www.asp.net")); var root = html.DocumentNode; var anchors = root.Descendants("a"); var unorderedLists = root.Descendants("ul");
You can further refine your search by specifying elements that have a particular attribute's value. This example searches for all elements with a class of "common-link":
var html = new HtmlDocument(); html.LoadHtml(new WebClient().DownloadString("http://www.asp.net")); var root = html.DocumentNode; var commonPosts = root.Descendants().Where(n => n.GetAttributeValue("class", "").Equals("common-post"));
Locating a specific piece of content
One of the uses of the HAP is for locating specific pieces of content in an HMTL document. The following example will demonstrate how to obtain the number of points I have been awarded as displayed on my profile page at the www.asp.net site:
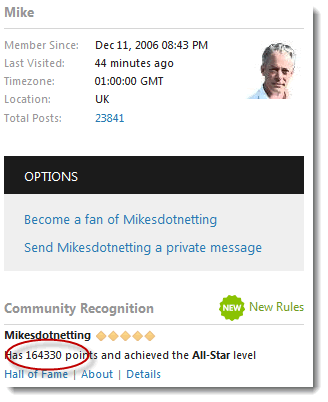
The first step is to examine the relevant HTML. I have only included a small section containing the content I am after, and have highlighted it below:
<div class="module-common"> <h2 class="common-header-underline transform-none"> Community Recognition <span class="recognition-new-rules"><a href="/t/2024428.aspx">New Rules</a></span> </h2> <div class="module-profile-recognition"> <h3>Mikesdotnetting</h3> <div class="post-rating All-Star"></div> <div class="clear"></div> <p>Has 164330 points and achieved the <strong>All-Star</strong> level</p> <a href="http://www.asp.net/community/recognition/hall-of-fame">Hall of Fame</a><span class="separator">|</span><a href="http://www.asp.net/community/recognition">About</a><span class="separator">|</span><a href="javascript:;" data-uitype="reputation-history" data-username="Mikesdotnetting">Details</a> <table> <thead> <tr><th>Location</th><th style="width:60%;">Activity</th><th style="width:10%;text-align:right">Points</th></tr> </thead> <tbody id="reputation-activities-container"> <tr> <td colspan="3" style="width:100%;height:65px;" class="busy"></td> </tr> </tbody> </table> </div> </div>
The content I want to target is located in a p element with no distinguishing features, such as an id or a class attribute.There are a number of other p elements within the document, so targeting them all won't be helpful. The best strategy is to target an easily identifiable single element, and then to navigate from there. There are a couple of fairly obvious candidates: a div with a class of "post-rating" and another with a class of "module-profile-recognition". If I was creating a tool to regularly parse the same live page, I would generally avoid targeting elements by class because, even though there may only be one on the page today (as is the case for both potential targets in this instance), more could be added in future. Therfore any assumptions about the number of elements is a brittle assumption. Id attributes, on the other hand, should be unique.
Having provided that warning, here's the code that starts with the element with a class of "module-profile-recognition":
var html = new HtmlDocument(); html.LoadHtml(new WebClient().DownloadString("http://forums.asp.net/members/Mikesdotnetting.aspx")); var root = html.DocumentNode; var p = root.Descendants() .Where(n => n.GetAttributeValue("class", "").Equals("module-profile-recognition")) .Single() .Descendants("p") .Single(); var content = p.InnerText;
The Descendants method returns a collection. Since there is only one div element matching the "module-profile-recognition" class selector, it is safe to use the Single method to return it. Then you can use the Descendants method to return all the child elements of the div that match the p selector. Again, there is only one, so it is safe to use the Single method to return the only paragraph. Finally, the text content is obtained via the InnerText property. An alternative property is the InnerHtml property, which returns all content, not just the text. Once you have the text content, you can perform Regex on it to extract just the numbers:
var points = Regex.Match(content, @"\d+").Value;
Summary
This is a brief introduction to the HtmlAgiltyPack which is the recommended tool for parsing HTML. It provides a familiar LINQ to Objects API which makes working with the library pretty easy. IF you need to parse or manipulate HTML, this is the only tool you need. Full documentation is available from the project's Codeplex site. Since it's a chm file, you will need to unblock it before you can use it. You do this by right-clicking on the file and going to its properties, then clicking the Unblock button.
